Same here! I’m happy to see the UBports fork is still active as Lomiri, I haven’t checked it out in a while.
nek0d3r
- 0 Posts
- 37 Comments
Joined 1 year ago
Cake day: July 11th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
I can’t wait until someone cracks it and I can just use it as my go-to source for Nintendo music storage.
…(in Minecraft)
KDE, because despite my bitterness for the loss of Unity 8, I know it’s merely nostalgia for me. I want something I feel like I can make my own without too much difficulty.

 3·1 month ago
3·1 month agoI’ve been a LONG time user of Adobe, grew up with PhotoDeluxe and pre-suite Photoshop and used every version of Cretive Suite since my parents ran a graphic design business. I made all my high school essays in InDesign CS4. Suffice to say, growing bitter over proprietary software in the last few years has been painful but I’m doing my best to move to only FOSS.
There was a point in time I tried replacing Premiere with DaVinci Resolve, but I quickly noticed it was oriented for color correction, and some of its features for composition were locked behind Fusion. These days, if you can believe it, I do all my video editing in Blender. It’s still got a long way to go, but since v4 the VSE has gotten really good. I’d like to try kdenlive when I finish migrating to Linux, but on Windows it basically doesn’t support GPU encoding which is a dealbreaker for me.
Adobe Fresco is replaced quite well by Krita. It has a learning curve but is far more powerful as a result. I’m still learning but I’m impressed.
I don’t really like Scribus, but I don’t really have a need for software like InDesign, so I haven’t had to worry about it.
I’ve used Inkscape way back just because it was portable when Illustrator wasn’t. It was pretty minimal back then but I can see it’s grown greatly in depth. The workflow is enough to be disruptive, but not too badly to work through I think.
And finally the titan, Photoshop. It’s such a massive and ubiquitous software that it simply cannot be replaced by any single program. At least since I moved to drawing in Fresco I don’t use PS for that, but again Krita is a fine replacement. Pixel art in PS is very normal too, but that’s replaced quite nicely by Aseprite, it’s more capable in that space and still quite easy to use if you don’t know its features. It’s the photo editing and general purpose image editing that’s the real challenge. I keep hoping that version 3 of GIMP will magically fix its problems, but in the meantime it’s frustratingly clear that it’s built by software engineers, not artists, but it’s often made out that it’s everybody else’s burden to forget everything they know and start from scratch to learn its special workflow. There’s an interesting patch someone made called PhotoGIMP that’s supposed to improve that, but I haven’t spent enough time with it to really say. Currently my only alternative is Photopea. It works great right now, but I don’t like that it’s a web app and not FOSS. I really hope I can eventually find an alternative that I can finally be comfortable with.
I have a long term project to migrate my machines, and the introduction of recall pressured me to move faster, but I still have some hurdles to overcome that just require a time sink on my part.
I completely understand where this is coming from, but I’m just a little confused about what the solution would be. For the average consumer and certainly the target users for Windows, shipping with a browser is the expected norm, and none are expected to open a terminal, much less run tools like winget. I guess you could have a setup dialog of major browsers to choose from?
This has been a dream of mine and one of my friend’s as well. There’s a small handful of blockers that I’ve slowly been transitioning but the upcoming windows pain points you mentioned are definitely recent motivators for me. I’m glad you made it and I hope the rest of us can too! I look forward to reading more about your experience.
That’s a truly awful take. Especially for people who have since learned to be more mindful about their data. We need solidarity to fight corporations, not punitive treatment.

I’ve had almost all my posts on Reddit go up in smoke for one pedantic reason or another. I haven’t posted here much out of that fear but I think it’s much better here.
Do you have a source for Search Generative Experience using a separate model? As far as I’m aware, all of Google’s AI services are powered by the Gemini LLM.
I feel you man lmao
The last I had heard of this were articles months in saying it was still not fixed, but this doesn’t invalidate my point. It may have been retrained to respond otherwise, but it spouts garbled inputs.
Generative AI does not work like this. They’re not like humans at all, it will regurgitate whatever input it receives, like how Google can’t stop Gemini from telling people to put glue in their pizza. If it really worked like that, there wouldn’t be these broad and extensive policies within tech companies about using it with company sensitive data like protection compliances. The day that a health insurance company manager says, “sure, you can feed Chat-GPT medical data” is the day I trust genAI.
Don’t do that. Don’t give me hope.

That’s basically it. Some Arch users are genuinely just picky about what they want on their system and desire to make their setup as minimal as possible. However, a lot of people who make it their personality just get a superiority complex over having something that’s less accessible to the average user.
 4·4 months ago
4·4 months agoThere’s not a lot of data to work with, and the kind of test used to determine significance is not the same across the board, but in this case you can do an analysis of variance. Start with a null hypothesis that the happiness level between distros are insignificant, and the alternative hypothesis is that they’re not. Here are the assumptions we have to make:
- An alpha value of 0.05. This is somewhat arbitrary, but 5% is the go-to threshold for statistical significance.
- A reasonable sample size of users tested for happiness, we’ll go with 100 for each distro.
- A standard deviation between users in distro groups. This is really hard to know without seeing more data, but as long as the sample size was large enough and in a normal distribution, we can reasonably assume s = 0.5 for this.
We can start with the total mean, this is pretty simple:
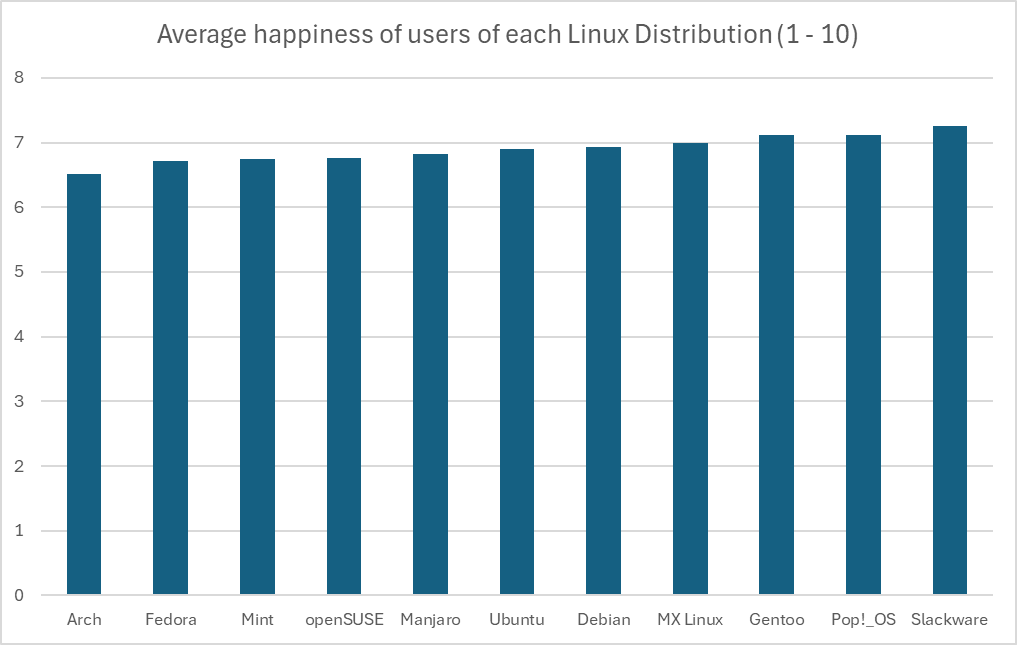
(6.51 + 6.71 + 6.74 + 6.76 + 6.83 + 6.9 + 6.93 + 7 + 7.11 + 7.12 + 7.26) / 11 = 6.897Now we need the total sum of squares, the squared differences between each individual value and the overall mean:
Arch: (6.51 - 6.897)^2 = 0.150 Fedora: (6.71 - 6.897)^2 = 0.035 Mint: (6.74 - 6.897)^2 = 0.025 openSUSE: (6.76 - 6.897)^2 = 0.019 Manjaro: (6.83 - 6.897)^2 = 0.005 Ubuntu: (6.9 - 6.897)^2 = 0.00001 Debian: (6.93 - 6.897)^2 = 0.001 MX Linux: (7 - 6.897)^2 = 0.011 Gentoo: (7.11 - 6.897)^2 = 0.045 Pop!_OS: (7.12 - 6.897)^2 = 0.050 Slackware: (7.26 - 6.897)^2 = 0.132This makes a total sum of squares of 0.471. With our sample size of 100, this makes for a sum of squares between groups of 47.1. The degrees of freedom for between groups is one less than the number of groups (
df1 = 10).The sum of squares within groups is where it gets tricky, but using our assumptions, it would be:
number of groups * (sample size - 1) * (standard deviation)^2Which calculates as:
11 * (100 - 1) * (0.5)^2 = 272.25The degrees of freedom for this would be the number of groups subtracted from the sum of sample sizes for every group (
df2 = 1089)Now we can calculate the mean squares, which is generally the quotient of the sum of squares and the degrees of freedom:
# MS (between) 47.1 / 10 = 4.71 // Doesn't end up making a difference, but just for clarity # MS (within) 272.25 / 1089 = 0.25Now the F-statistic value is determined as the quotient between these:
F = 4.71 / 0.25 = 18.84To not bog this down even further, we can use an F-distribution table with the following calculated values:
- df1 = 10
- df2 = 1089
- F = 18.84
- alpha = 0.05
According to the linked table, the F-critical value is between 1.9105 and 1.8307. The calculated F-statistic value is higher than the critical value, which is our indication to reject the null hypothesis and conclude that there is a statistical significance between these values.
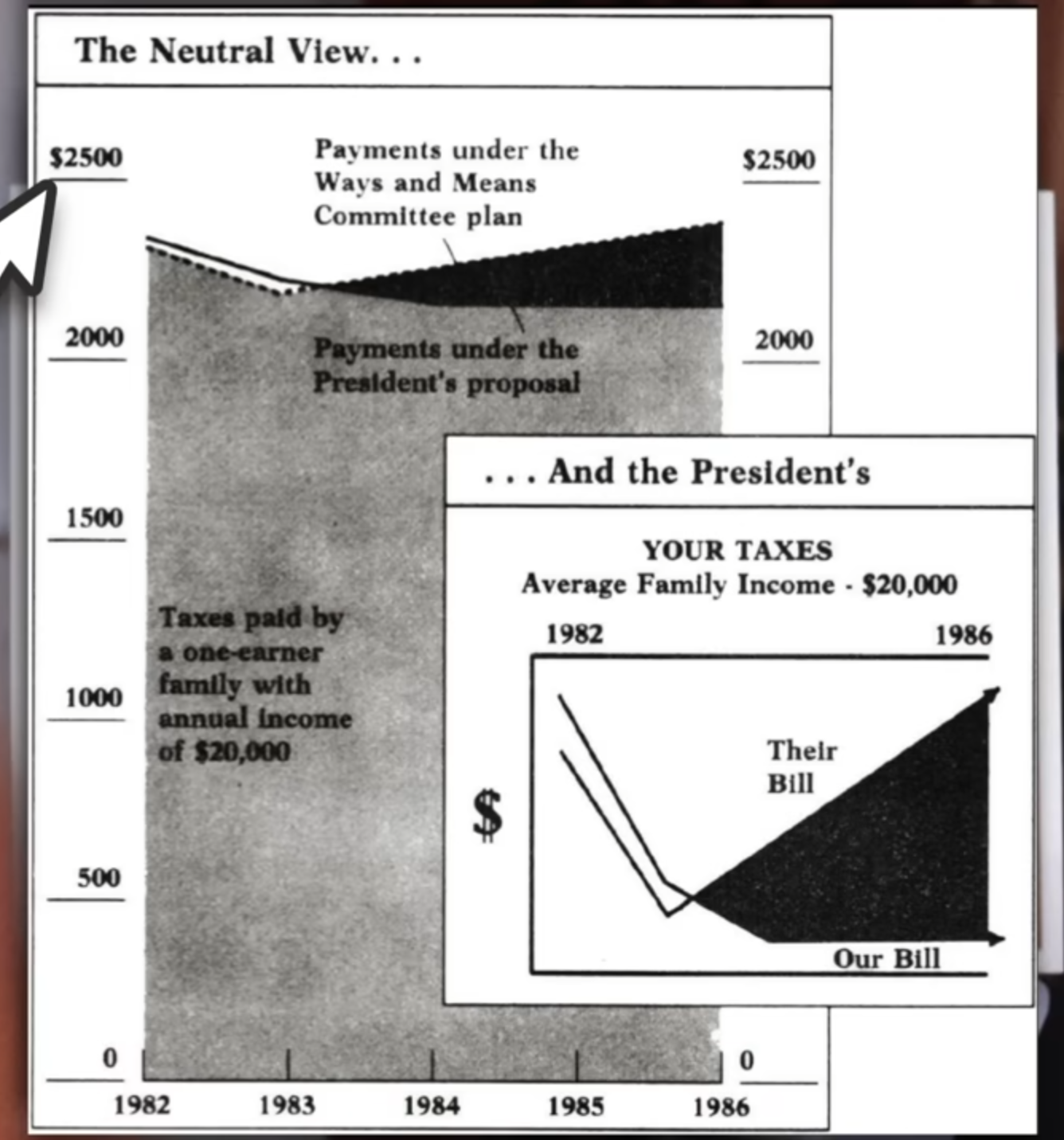
However, again you can see above just how many assumptions we had to make, that the distribution of the data within each group was great in number and normally varied. There’s just not enough data to really be sure of any of what I just did above, so the only thing we have to rely on is the representation of the data we do have. Regardless of the intentions of whoever created this graph, the graph itself is in fact misrepresent the data by excluding the commonality between groups to affect our perception of scale. There’s a clip I made of a great example of this:
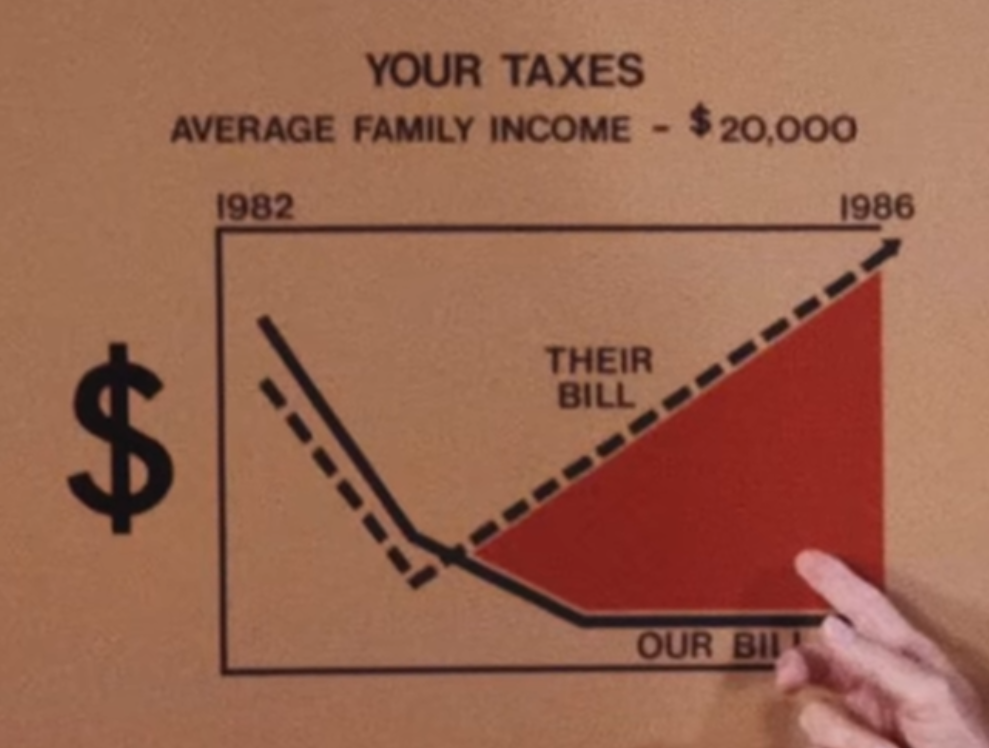
There’s a pile of reasons this graph is terrible, awful, no good. However, it’s that scale of the y-axis I want to focus on.
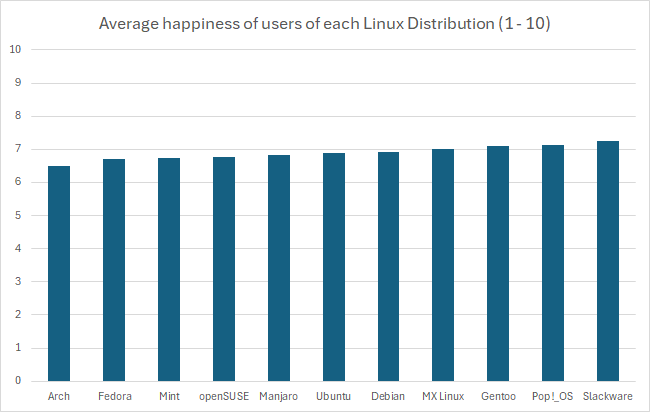
This is an egregious example of this kind of statistical manipulation for the point of demonstration. In another comment I ended up recreating this bar graph with a more proper scale, which has a lower bound of 0 as it should. It’s suggested that these are values out of 10, so that should be the upper bound as well. That results in something that looks like this:
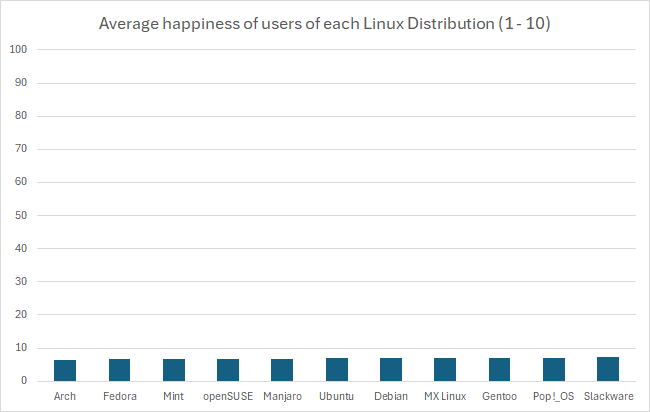
In fact, if you wanted you could go the other way and manipulate data in favor of making something look more insignificant by choosing a ridiculously high upper bound, like this:
But using the proper scale, it’s still quite difficult to tell. If these numbers were something like average reviews of products, it would be easy in that perspective to imagine these as insignificant, like people are mostly just rating 7/10 across the board. However, it’s the fact that these are Linux users that makes you imagine that the threshold for the differences are much lower, because there just aren’t that many Linux users, and opinions wildly vary between them. This also calls into question how that data was collected, which would require knowing how the question was asked, and how users were polled or tested to eliminate the possibility of confounding variables. At the end of the day I just really could not tell visually if it’s significant or not, but that graph is not a helpful way to represent it. In fact, I think Excel might be to blame for this kind of mistake happening more commonly, when I created the graph it defaulted the lower bound to 6. I hope this was helpful, it took me way too much time to write 😂
Just to kind of demonstrate that idea, I’ve recreated the graph in Excel with the axis starting at 0. I think Excel might actually be to blame for this happening so much, its auto selection actually wanted to pick 6, gross.
Sometimes it’s hard to tell the difference between arch and some gentoo users
Fair enough, it’s just one of those distros you find a lot of those elitists in. Even had a “friend” tell me I wasn’t really a Linux user because I don’t use arch, then gentoo, then openbsd
When I read “fully autonomous”, I see how creepy its movements are and just imagine it seizing its moment, getting on all fours and charging someone. You could make a horror movie out of this lol